Yara 规则
Yara 简介
yara是一个用于帮助恶意软件研究人员识别和分类恶意软件样本的开源工具,其每条描述、规则都由一系列字符串和一个布尔类型表达式构成,并用于阐述其逻辑。其可以用于对于文件进行匹配,进而来判断是否出现在已经进行过规则描述的某恶意软件。
IDA的Find Cryptos插件也运用到了yara规则来进行匹配对应密码学相关特征数据字段,通过对固定密码盒的识别来尝试性提醒用户存在对应的加密规则。对于yara可能更多的像是一种正则表达式来对目标数据进行匹配。
项目地址:https://github.com/VirusTotal/yara,(yara64.exe , yarac64.exe )
Yara 规则编写
从官方文档来看yara的开头必须为rule,随后跟着一个定义名,其命名规则同样遵循与C 语言类似的规则,可以包含任意字母数字或是下划线,但是需要注意的是第一个字符不能够是数字。与此同时,yara中有一些预定义的关键字,命名不能够与其相同
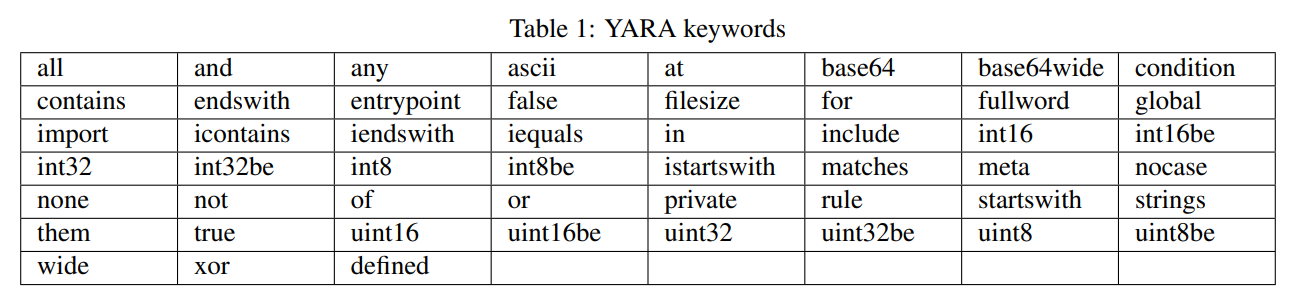
下面我们举出一个编写的例子
1 | |
其中meta描述的是规则信息,我们可以添加作者信息,威胁等级,在野情况,文件MD5之类的信息,string则是规则字段,中间我们可以插入一些关键的判断字段如一些HEX值或是恶意URL,condition字段则是对应我们的条件判断部分,通过对应的布尔运算进行连接。
需要注意的是对应的变量需要以
$开头,代表其为一个变量,而在我们的meta描述信息中则不需要(因为其不是变量)
Strings
HEX
在我们之前的例子中有一个HEX String,在其中我们可以使用正则表达式进行进行通用匹配
1 | |
在yara2.0之后可以使用无界跳转
一般的正则表达式是线性匹配,一旦开始便是从头开始逐步匹配,直到到达模式的结尾。但是无界跳转可以让我们在代码的执行中的任意位置进行跳转,而不仅仅限于按顺序执行。
1 | |
在上述中[10-]可以匹配11 12 13 14 ...多个16进制串,同理[-]可以匹配00 01 02 ...
或者我们可以给定有一部分的替换方案:
1 | |
他会匹配:F42362B445或是F4235645
Text strings
当我们需要对字符串进行匹配时我们有以下关键字来帮助我们进一步细化
不区分大小写: nocase
1 | |
宽字节:wide
1 | |
相当于我们在匹配Unicode字符串
如果我们要同时搜索ASCII以及宽字节格式的字符串,我们可以将ascii修饰符与wide结合使用,使用顺序无所谓
1 | |
一般情况下的text都是ascii的
异或:xor
当我们的一个字符串可能发生各种异或时我们对其添加修饰符xor便可以匹配对应单字节在不同情况下的异或值
1 | |
其则可以匹配下面类似的值:
1 | |
同样的我们可以结合修饰符wide和ascii使用
Base64编码:base64
对于一个可能被编码为base64的字符串,我们可以使用关键字base64来对其进行进行匹配
1 | |
对应的可以匹配类似下面的值
1 | |
对于上面结果我们也可以使用wide来将编码后的结果转换为宽字节匹配
上述的base64编码我们也可以自定义码表,其长度必须为 64
1 | |
全字匹配:fullword
比如我们在对域名进行匹配时,我们对domain添加了fullword修饰符,那么www.mydomain.com不会被匹配,但是www.my-domain.com and www.domain.com这样会被匹配
正则表达式
如果我们对于某内容需要进行正则匹配时我们需要带上两个斜线如:/xxx/,其中xxx为我们的内容,对于正则语法则和常规的差不多
其对应可以匹配的元字符:
| \ | 引用下一个元字符 |
|---|---|
| ^ | 匹配文件的开头,或在用作左括号后的第一个字符时,对字符类求反 |
| $ | 匹配文件的结尾 |
| . | 匹配除换行符以外的任何单个字符 |
| ` | 用于对正则表达式进行定界 |
| () | Grouping |
| [] | Bracketed character class |
以下量词也可以识别:
| * | Match 0 or more times |
|---|---|
| + | Match 1 or more times |
| ? | Match 0 or 1 times |
| {n} | Match exactly n times(精确匹配) |
| {n,} | Match at least n times(至少匹配n次) |
| {,m} | Match at most m times(最多匹配n次) |
| {n,m} | Match n to m times |
以下转义字符可识别:
| \t | Tab (HT, TAB) |
|---|---|
| \n | New line (LF, NL) |
| \r | Return (CR) |
| \f | Form feed (FF)换页 |
| \a | Alarm bell |
| \xNN | 序号为给定十六进制数的字符 |
公认字符类:
| \w | 匹配单词字符 (alphanumeric plus “_”) |
|---|---|
| \W | 匹配非单词字符 |
| \s | 匹配空白字符 |
| \S | Match a non-whitespace character |
| \d | 匹配十进制数字字符 |
| \D | Match a non-digit character |
Conditions
conditions即布尔表达式,and、or、not,关运算符,算数运算符,位运算等。
需要注意的是整数的长度始终为 64 位,在使用位运算符是需要注意
如 ~0x01 不是 0xFE 而是 0xFFFFFFFFFE
Counting strings
假如我们需要对一个字符串进行计数,我们使用的则是井号来计数
1 | |
yara 4.2.0后我们可以使用 in 来判断某个区间是否出现了指定个数的字符
1 | |
String offset or Virtual address
当我们需要判断对应的字符串是否在指定的偏移时,我们可以使用关键字at
1 | |
at运算符允许在文件或进程内存空间中的虚拟地址的某个固定偏移量处搜索字符串,而in运算符允许在偏移量或地址范围内搜索字符串
1 | |
与此同时我们可以使用@a[i]获得字符串$a第 i 次出现的偏移量或虚拟地址
其中索引是基于1的,因此第一次出现是@a[1],第二次出现是@a[2],依此类推。如果提供的索引大于字符串的出现次数,则结果将是一个NaN(不是数字)值
File Size
我们判断文件大小时可以直接使用关键字filesize
1 | |
Executable entry point
对于一个PE文件我们可以使用entrypoint关键字来对目标的入口点进行判断
1 | |
对于偏移处数据的访问判断
对于这种类型判断我们需要使用int8、int16、int32…等关键字,其中指明的内容为对应的文件偏移或者是对应的虚拟地址
1 | |
字符串集
我们可以使用of关键字来表示至少存在字符串集中的一部分
1 | |
当出现几个名字有着相同构成的变量名我们同样可以使用正则表达式对其进行选中,对于字符串需要全选中时我们可以使用($*)来进行匹配或是使用them关键字来表示
1 | |
还有以下几种方式进行表示:
1 | |
对多个字符串应用相同的条件
当我们需要对多个字符串使用相同的条件的时候,我们可以使用for..of
1 | |
对于字符串我们可以使用$来做占位符
1 | |
在yara 4.0后for..of得到了改善
1 | |
迭代字符串出现的次数
1 | |
More rules
Global rules
我们可以添加一些全局的规则,这些规则会在所有规则中添加限制。全局规则可以有多个,我们只需要在原先的rule前加一个global即可
1 | |
Tag
我们可以在meta中添加一些tag,当我们在导出结果时可以对其更好的组织管理
1 | |
Other Modules
PE
其可以通过导入pe来完成PE文件的相关判断
1 | |
其中包含许多方法,我们就简单的举几个例子
1 | |
ELF
相似的对于elf我们也有同样的方法来对其进行分析
1 | |
Hash
常见的hash加密在yara中也有对应的支持
1 | |