NVDIA Instant-ngp 复现
前言
受到学校大创的不可抗力因素,以及某位摆烂队友的原因,最终选择方向为三维环境重建,而目前唯一的进度就只有这个。
因个人能力有限只能在本文中简单的对此项目进行复现,并指出一些方式来作为数据源给Instant-ngp作为输入源,进行训练
本次复现环境为 Windows10、CUDA 11.7、Python 3.8 (numpy 1.24.4、opencv-python 4.5.5.64)
项目地址:NVlabs/instant-ngp: Instant neural graphics primitives: lightning fast NeRF and more (github.com)
论文简介
其论文标题翻译为中文为使用哈希编码的多分辨率的即时神经图形原语,我们从文中可以看到这样一张图

通过对比观察我们可以明显的看出对应的训练速度十分快速,而这也正是NGP所拥有的特点,与此同时其还支持CUDA进行编程,意味着我们可以使用N卡(Nvidia显卡)进行计算,加快对应的渲染速度
其对应的核心是多分辨哈希编码,相比NeRF的初始研究上,使用全连接神经网络的神经图形原语
NeRF训练和评估是非常耗时的,而NGP设计了一个新的通用性的输入编码,它可以使用小型的网络同时又不会降低质量小型的网络,可以显著的减少浮点数的计算和内存访问
输入编码的几种方式
频率编码
在原始的过程中其使用的是类似cos、sin的三角函数进行线性变换将低频转换为高频,以此将三维转换到高维中便于机器的学习
参数编码
参数编码则是除了权重以及偏置职位,增加了一种辅助类型的数据结果,如网格或者是数字。此方式可能会消耗更多的内存,但是在此方式可以快速的进行训练,其在更新数据时只更新对应有影响的点位
稀疏参数编码
在上面的密集型参数编码中使用了更多的存储,对于密集型参数编码存在两种浪费:
- 在定义的空间中的空白部分是无意义的,但是会占用对应空间
- 密集型网格可能会对线性差值进行过度的平滑
而稀疏参数编码则主要解决上述问题
多分辨率哈希编码
此编码变为ngp的一个核心内容
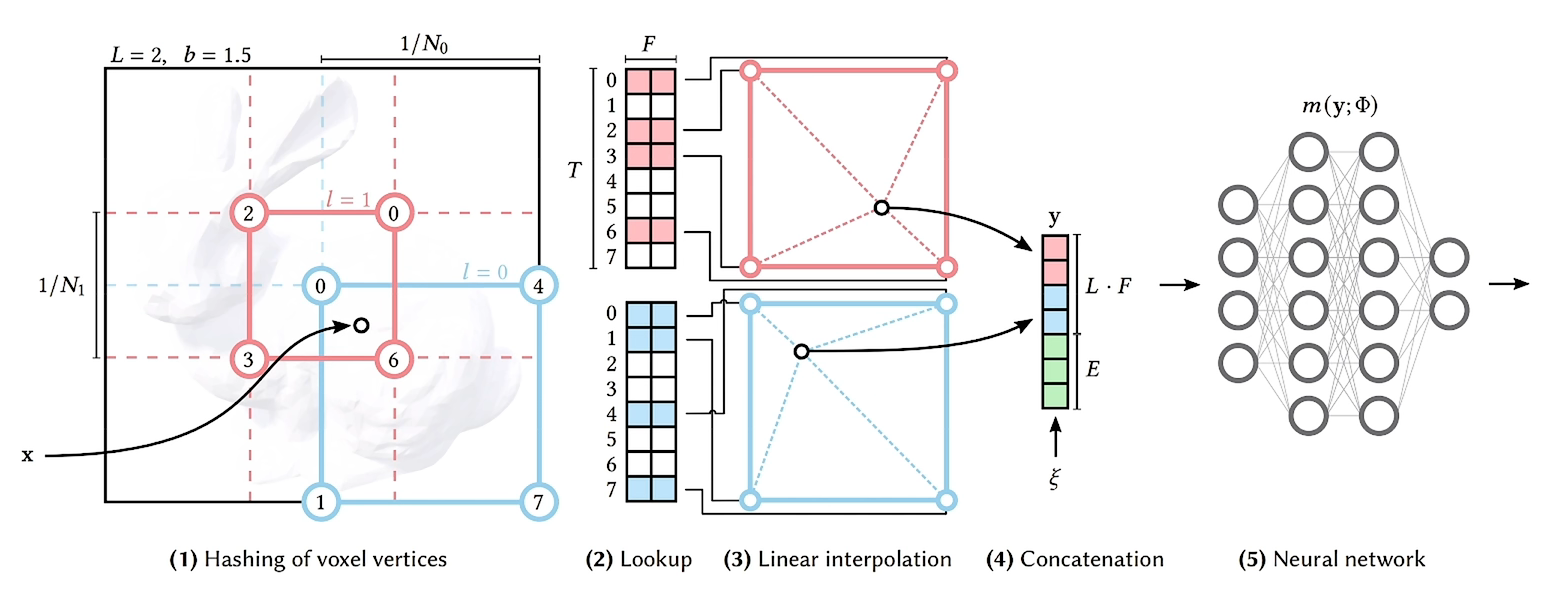
假设这个表示神经网络: $$m(y, \varphi)$$
这个表示输入编码:$$y = enc(x,\theta)$$
在保证相同的质量的情况下,达到更好的训练速度,同时不会增加开销
第一步是将坐标点(x,y,z的真实值)转换为hash表中的index。途中蓝色粉色表示了不同的Level下的计算,不同的Level,网格的分辨率不同(上图中粉色网格小,粉色的分辨率就比蓝色的大,也就是蓝色的为更低级的层级)
第二步是在不同层级的hash table中找到目标值周围的八个点位的值,然后进行三线性插值
第三步就是将所有的Level的结果拼接,到这里就算完成了encoding
第四步就是送入神经网络即可 (如果两个点在索引到table上时为同一个点时,神经网络可以帮助我们解决哈希碰撞的问题)
NGP中不仅网络权重要进行训练,编码参数也要进行训练参数编码
其设计为 L 层,每层有 T 个特征向量,每个向量的维度是 F,有如下超参数

对于分每层的分辨率的计算依靠以下公式进行计算:
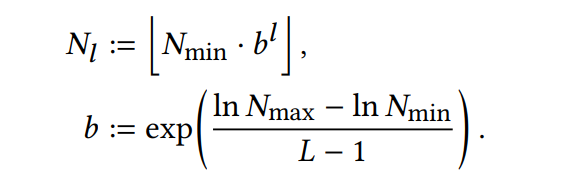
而我们进行哈希索引到table的公式如下:
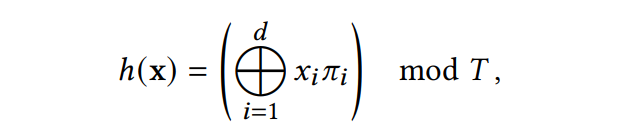
上述公式中的 $$x_i$$ 的下标表示的是每一个xyz坐标上的一个分量,而 $$\pi_i$$ 被设计为一个巨大的质数
源码简介
项目地址(pytorch 实现)
对应代码文件的核心为以下文件:
-
opts
-
load_blender_data
-
run_nerf
-
nerf_helpers
-
nerf_model
-
render
-
inference
简易流程
- load_blender_data
pose_spherical
- create_nerf
get_embedder
create Embedder
train中调用 lambda network_query_fn
- in train iteration
use_batching or not
get_rays
render (训练相关代码从此开始)
rays_0, rays_d = get_rays(H, W, K, c2w)
batchify_rays 分批处理
render_rays
准备工作
分解出 rays_o, rays_d, viewdirs, near, fear
构造采样点,给采样点加入随机噪声
Network_query_fn(pts, viewdirs, network_fn) 用在create_nerf中的lambda函数
run_natwork
xyz pe
viewdirs pe
batchify 在这里调用的fn就是 NeRF model
将 pts, viewdirs 分开
Pts 经过 8 层 linear
8 层后的输出经过一层linear输出Alpha
8层厚的输出再来一层linear(feature Linear)
Feature 和input_view拼接 再经过一层linear
最后在经过一层linear得到RGB
Raw2outputs 体渲染
Sample_pdf(z_vals_mid, weights, N_importance) 精细网络使用的采样方案
Network_query_fn(pts, views, network_fn) 第二次精细网络渲染
Raw2outputs 体渲染
Img2mse
Mse2psnr
调整学习率
定期保存模型,定期生成测试视频,定期渲染测试数据
测试
为保证训练效率,此次复现工作主要采用CUDA实现版本完成
项目链接:NVlabs/instant-ngp: Instant neural graphics primitives: lightning fast NeRF and more (github.com)
准备工作 —— 环境搭建
在编译instant_ngp代码之前需要准备以下几样东西:
- Visual Studio 2019。必须是2019,当然我只在2019上编译过,没有在其他版本的Visual Studio上尝试过,但是听说只有Visual Studio 2019才可以。
- cuda。官方给的是cuda v10.2以上,我使用的是cuda11.6,我使用的显卡是3090,之前用的cuda11.3,但是好像失败了,就又安装了11.6,如果你的cuda版本不能用,又不想卸载之前的cuda,那么我建议安装两个版本的cuda,根据情况切换,具体操作网上有很多,大家自行查看。当然,还要下载对应的cudnn。
- Cmake。官网建议3.21以上。
- python。官网建议3.7及其以上。非必须,但是建议安装。
- OptiX。官网建议7.3以上。非必选,但是意见安装。
以上所有内容安装之后一定要检查环境,是否将路径添加到环境中。
TODO: 等后期补充详细信息
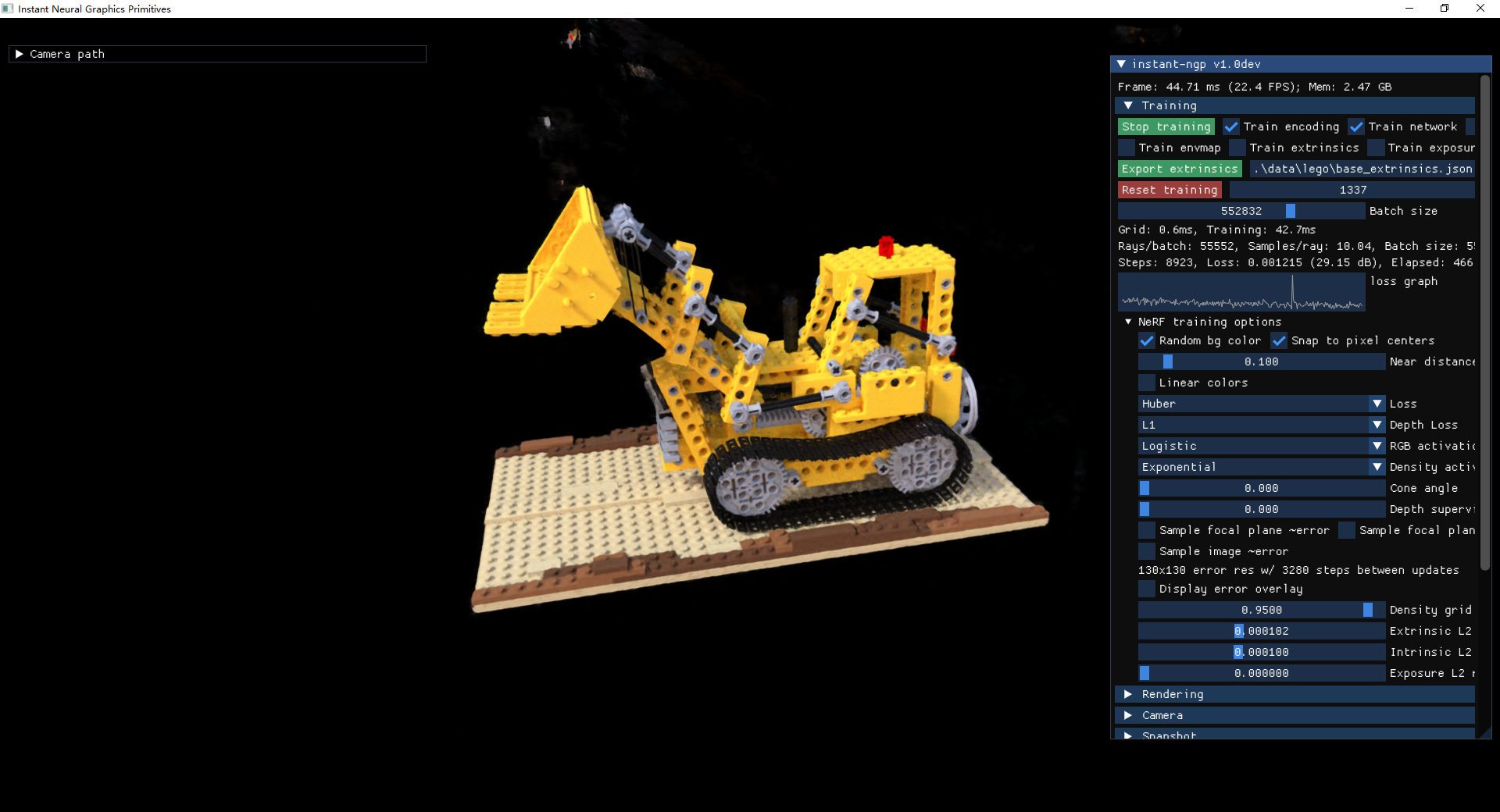
运行截图
扩展
上述过程中我们已经将对应的论文进行复现,以及论文中相关的测试数据我们也可以成功的复现,此处我们添加一些我们自己的扩展数据,主要用到colmap、Python-Opencv以及numpy来进行完成对应工作
Colmap
colmap(Structure-from-Motion and Multi-View Stereo)是一个功能强大的开源软件包,用于从图像序列中重建三维场景。它结合了结构从运动(Structure-from-Motion,SfM)和多视角立体(Multi-View Stereo,MVS)的技术,能够从一组图像中估计相机的位姿、场景的几何结构以及像素级的深度信息。
colmap的主要功能包括:
- 图像导入与管理:
colmap支持导入常见的图像格式,并提供一个图像数据库来管理和组织您的图像数据。 - 特征提取与匹配:
colmap可以自动从图像中提取特征点,例如SIFT、SURF等,并使用特征匹配算法(例如基于描述符的匹配)在不同图像之间建立特征点的对应关系。 - 相机定位与三维重建:
colmap利用图像的特征匹配信息来估计相机的位姿(旋转和平移矩阵),并同时进行三维场景的重建。它使用了一种增量式的方法,逐步优化相机位姿和场景的几何结构。 - 稠密点云重建与立体匹配:
colmap可以进一步提供稠密的三维点云重建和立体匹配的功能,通过将多个视角的信息融合在一起,生成更密集的场景表示。 - 导出与可视化:
colmap支持导出重建结果的各种格式,包括点云、相机位姿、表面模型等。此外,它还提供了一些可视化工具,用于查看和分析重建结果。
colmap的优点之一是其开源性质,使得研究者和开发者可以自由地使用、修改和扩展其功能。它在学术界和工业界都被广泛使用,用于各种计算机视觉和三维重建任务,例如增强现实、虚拟现实、机器人导航等。
拆分视频
通常来说我们所拿到的数据源是一般为视频文件,我们需要从中拿到相机的位姿数据则需要我们使用colmap来完成,colmap获取相机位姿之前我们需要使用Python-Opencv来帮组我们对视频图像流进行一定的优化处理,我们编写以下脚本来进行拆分
1 | |
上述代码中我们通过匹配对应的相似帧的阈值,以及相关的视频帧间隔来进行拆分,大致上我们拆分一个视频可以拿到大约150+左右的图片后便可以进行后续的工作
图片训练
我们利用colmap进行获取相机位姿数据,并训练相关的深度图,大致可以得到以下图:

之后我们将其数据导出为txt,在这之前NeRF仍然无法处理这个数据,我们还需要使用一个脚本将其进行转换,此处用到Nvidia官方给出的Python脚本,colmap2nerf.py其提供以下内容:
--video_in:可选参数,指定要转换为图像的视频文件路径。--video_fps:可选参数,指定从视频中提取图像时的帧率。--time_slice:可选参数,指定从视频中提取图像的时间范围,格式为t1,t2,表示从第t1秒到第t2秒的时间段。--run_colmap:可选参数,如果设置,则在图像文件夹上先运行 COLMAP。--colmap_matcher:可选参数,指定 COLMAP 应该使用的匹配器类型。可选值为exhaustive、sequential、spatial、transitive、vocab_tree。--colmap_db:可选参数,指定 COLMAP 数据库文件的名称。--images:可选参数,指定图像文件夹的路径。--text:可选参数,指定 COLMAP 文本文件的路径。如果使用--run_colmap参数,则该路径将被自动设置。--aabb_scale:可选参数,指定场景的缩放因子。可选值为1、2、4、8、16,其中1表示场景适合单位立方体,其他值是 2 的幂次。--skip_early:可选参数,指定跳过开始的图像数量。--out:可选参数,指定输出路径,用于保存转换后的相机位姿数据。
此处我们主要使用--images、--text以及--out参数来将我们之前的东西进行转换
1 | |
拿到相关的匹配后的json数据后我们便可以将其丢入NeRF中进行处理了
1 | |
之后我们可以调整对应的训练参数,进行相应的训练即可
训练一段时间后我们可以得到以下图片:
