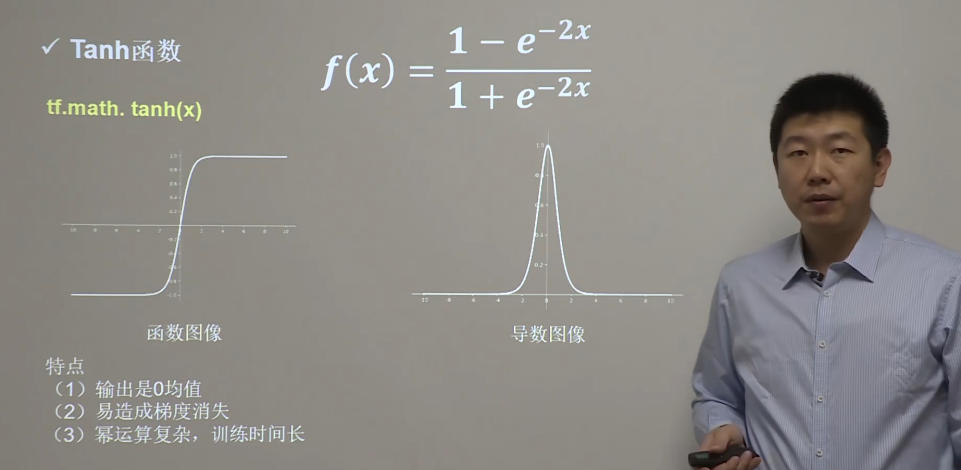前言
本笔记算是对 北京大学 软件与微电子学院 曹健老师 的人工智能实践课程的总结与归纳,收录了课程中的一些函数以及思想方法,方便后来人学习
学习视频链接:人工智能实践:Tensorflow笔记_中国大学MOOC(慕课)
Tensorflow & Numpy 部分函数基础入门
张量概念
维数
阶
名字
例子
0-D
0
标量 scalar
s = 1 2 3
1-D
1
向量 vector
v = [1,2,3]
2-D
2
矩阵 matrix
m = [[1,2,3],[4,5,6],[7,8,9]]
n-D
n
张量 tensor
t = [[[ …]]] (有n个[])
张量可以表示 0 阶到 n 阶数组 (列表)
张量创建
1 2 3 4 5 6 7 8 9 10 11 import tensorflow as tf
随机数生成
1 2 3 4 5 import tensorflow as tf
在tf.truncated_normal中如果随机生成数据的取值在(μ-2σ,μ+2σ)之则重新进行生成,保证了生成值在均值附近。
1 2 3 4 5 6 7 8 9 import numpy as np1 )2 ,3 )
常用函数
1 2 3 4 5 6
索引
axis : axis 代表着在一共二维张量或者数组中,可以通过调整 axis 等于 0或者 1 控制执行维度,axis=0时代表跨行,即对列进行操作。当axis=1的时候代表跨列,即对列进行操作,如果不指定 axis 则所有元素参与计算
1 2 3 4
当我们需要返回沿着指定维度最大值或者最小值的索引使,我们可以使用如下函数
1 2 3 4 5 6 7 tf.argmax(张量名,axis=操作轴)0 )1 )
将变量标记为”可训练“
数学运算
需要注意维度相同的张量才可以做四则运算
1 2 3 4 5 6 pow tf.sqrt
将标签与张量进行配对构成数据集
1 2
某个函数对指定参数求导计算
1 2 3 4 5 with tf.GradientTape() as tape:
枚举 enumerate
返回对应的索引以及元素通常在 for 循环中使用
1 2 3 4 5 6 7 8 9 10 enumerate (列表名)'one' , 'two' , 'three' ]for i, element in enumerate (seq):print (i, element)0 one1 two2 three
标签
对于标签我们常用独热编码表示标签
独热编码:在分类问题中常用独热码做标签,标记类别:1表示是,0表示非
我们可以使用下面的函数,将待转换数据直接转换为独热码形式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import tensorflow as tf2 1 , 0 , 2 ]) print ("result of labels1:" , output)print ("\n" )0. 1. ]1. 0. ]0. 0. ]], shape=(3 , 2 ), dtype=float32)
概率统计
对于分类问题,神经网络完成前向传播,计算出了每种类型的可能性大小,需要输出符合了概率分布时,才可以与独热码的标签作比较
1 2 3 4 5 6 7 8 1.01 ,2.01 ,-0.66 ])print ("After softmax,y_pro is:" ,y_pro)is :tf.Tensor([0.25598174 0.69583046 0.0481878 ],shape=(3 ,),dtype=float32)
一般情况下我们将神经网络正向传播后的结果组成张量然后使用该函数对其进行统计概率分布,对于高维我们还可以使用 squeeze 去除大小为 1 的维度
1 2
或者,要删除特定的大小为1的维度:
1 2 2 , 4 ]))
参数自更新
1 2 3 4 5 6 7 8 9 4 )1 ) print (w)'Variable:0' shape=() dtype=int32, numpy=3 >
条件判别
1 2 3 4 5 6 7 8 9 10 11 import tensorflow as tf1 , 2 , 3 , 1 , 1 ])0 , 1 , 3 , 4 , 5 ])print ("c:" , c)1 2 3 4 5 ], shape=(5 ,), dtype=int32)
垂直叠加
网格坐标点生成
1 2 3 4 5 6 7 1 ,数组2 ,...]
神经网络(NN)复杂度
我们对于神经网络的复杂度统计只统计具有运算能力的层,同时在输入层和输出层中间的所有层都称之为隐藏层
学习率
指数衰减学习率
可以先用较大的学习率,快速得到最优解,然后逐步减小学习率,使模型在训练后期稳定
初始学习率 与 学习衰减率 与 多少轮衰减一次 为超参数
激活函数
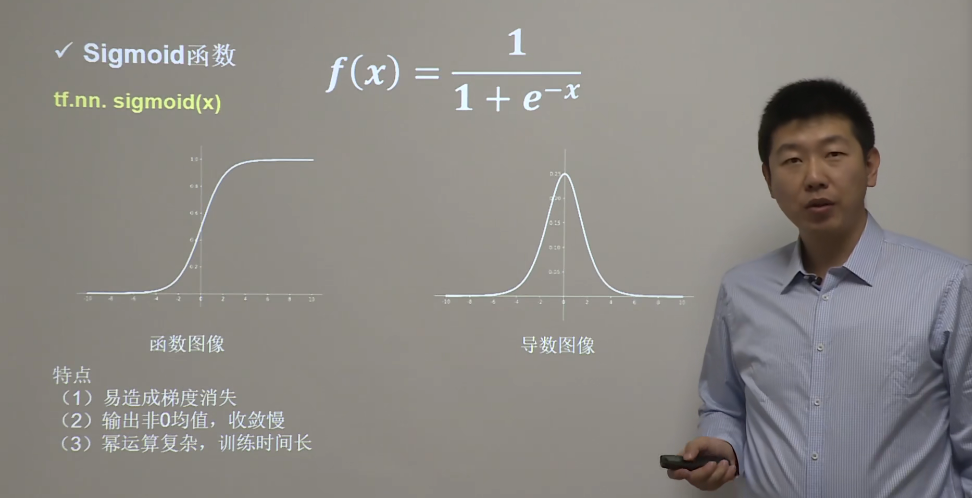
Sigmoid 函数
Sigmoid函数也叫Logistic函数,用于隐层神经元输出,取值范围为(0,1),它可以将一个实数映射到(0,1)的区间,可以用来做二分类。在特征相差比较复杂或是相差不是特别大时效果比较好。sigmoid是一个十分常见的激活函数,函数的表达式如下:
在什么情况下适合使用 Sigmoid 激活函数呢?
Sigmoid 函数的输出范围是 0 到 1。由于输出值限定在 0 到1,因此它对每个神经元的输出进行了归一化;
用于将预测概率作为输出的模型。由于概率的取值范围是 0 到 1,因此 Sigmoid 函数非常合适;
梯度平滑,避免「跳跃」的输出值;
函数是可微的。这意味着可以找到任意两个点的 sigmoid 曲线的斜率;
明确的预测,即非常接近 1 或 0。
Sigmoid 激活函数存在的不足:
梯度消失 :注意:Sigmoid 函数趋近 0 和 1 的时候变化率会变得平坦,也就是说,Sigmoid 的梯度趋近于 0。神经网络使用 Sigmoid 激活函数进行反向传播时,输出接近 0 或 1 的神经元其梯度趋近于 0。这些神经元叫作饱和神经元。因此,这些神经元的权重不会更新。此外,与此类神经元相连的神经元的权重也更新得很慢。该问题叫作梯度消失。因此,想象一下,如果一个大型神经网络包含 Sigmoid 神经元,而其中很多个都处于饱和状态,那么该网络无法执行反向传播。不以零为中心 :Sigmoid 输出不以零为中心的,,输出恒大于0,非零中心化的输出会使得其后一层的神经元的输入发生偏置偏移(Bias Shift),并进一步使得梯度下降的收敛速度变慢。计算成本高昂 :exp() 函数与其他非线性激活函数相比,计算成本高昂,计算机运行起来速度较慢。
Tanh 函数
Tanh 激活函数又叫作双曲正切激活函数(hyperbolic tangent activation function)。与 Sigmoid 函数类似,Tanh 函数也使用真值,但 Tanh 函数将其压缩至-1 到 1 的区间内。与 Sigmoid 不同,Tanh 函数的输出以零为中心,因为区间在-1 到 1 之间。
函数表达式:
在实践中,Tanh 函数的使用优先性高于 Sigmoid 函数。负数输入被当作负值,零输入值的映射接近零,正数输入被当作正值:
当输入较大或较小时,输出几乎是平滑的并且梯度较小,这不利于权重更新。二者的区别在于输出间隔,tanh 的输出间隔为 1,并且整个函数以 0 为中心,比 sigmoid 函数更好;
在 tanh 图中,负输入将被强映射为负,而零输入被映射为接近零。
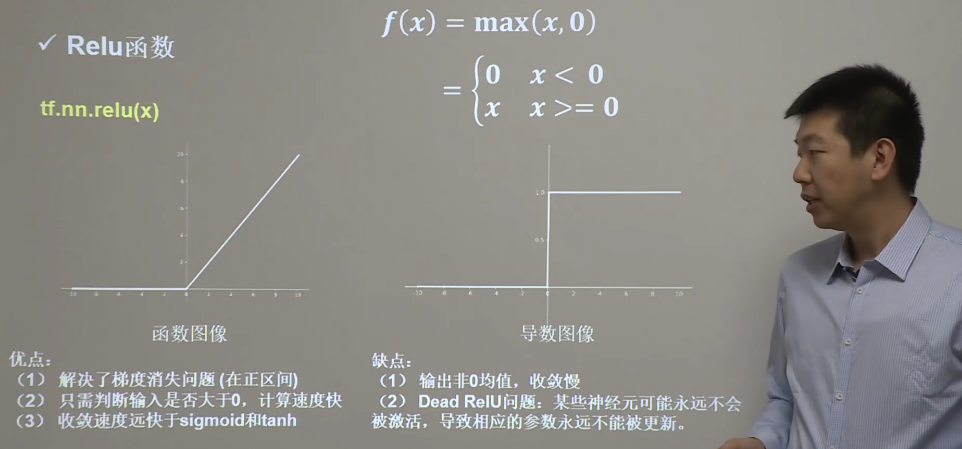
Relu 函数
ReLU函数又称为修正线性单元(Rectified Linear Unit),是一种分段线性函数,其弥补了sigmoid函数以及tanh函数的梯度消失问题,在目前的深度神经网络中被广泛使用。ReLU函数本质上是一个斜坡(ramp)函数,公式及函数图像如下:
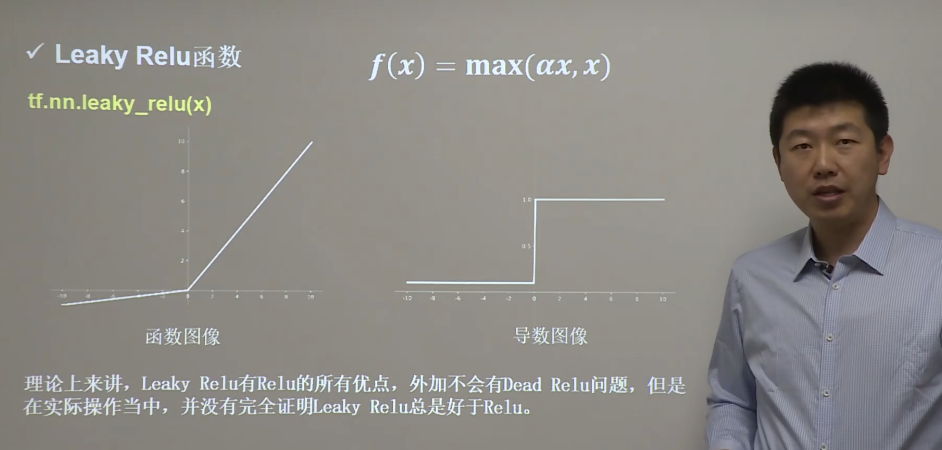
Leaky Relu 函数
为了解决 ReLU 激活函数中的梯度消失问题,当 x < 0 时,我们使用 Leaky ReLU —— 该函数试图修复 dead ReLU 问题。
函数表达式以及图像如下:
softmax
Softmax 是用于多类分类问题的激活函数,在多类分类问题中,超过两个类标签则需要类成员关系。对于长度为 K 的任意实向量,Softmax 可以将其压缩为长度为 K,值在(0,1)范围内,并且向量中元素的总和为 1 的实向量。
函数表达式如下:
Softmax 激活函数的不足:
在零点不可微;
负输入的梯度为零,这意味着对于该区域的激活,权重不会在反向传播期间更新,因此会产生永不激活的死亡神经元。
一些建议 —— 对于初学者
首选relu激活函数
学习率设置较小值
输入特征标准化,即让输入特征满足以 0 为均值,1 为标准差的正态分布
初始参数中心化,即让随机生成的参数满足以 0 为均值,$\sqrt{\frac{2}{当前层输入特征个数}}$为标准差的正态分布
损失函数
损失函数(loss):预测值(y)与已知答案(y_)的差距
NN优化目标 -> loss 最小
mse 损失函数
$$
1 loss_mse = tf.reduce_mean(tf.square(y-y_))
自定义损失函数
$$
y_ : 标准答案数据集的 y : 预测答案计算出的
即我们可以自己定义对应不同情况下的损失率,对于不同的情况下定义相应的 f(y_,y)
交叉熵 CE
其表示两个概率分布之间的距离
1 tf.losses.categorical_crosseentropy(y_,y)
当交叉熵越小时,对应的预测更为准确
一般来说我们通常先将输出通过 softmax 转换为符合概率分布的结果,再计算 y 与 y_ 的交叉熵损失函数
1 2 3 4 tf.nn.softmax_cross_entropy_with_logits(y,y_)
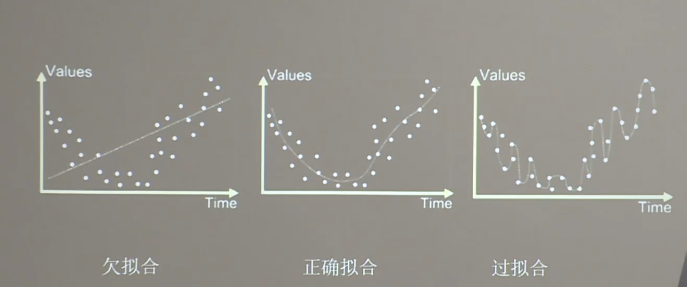
欠拟合与过拟合
对于欠拟合我们有如下解决方法:
增加输入特征选项
增加网络参数
减少正则化参数
对于过拟合我们有如下方法:
数据清洗
增大训练集
采用正则化
增大正则化参数
正则化:在损失函数中引入模型复杂度指标,通过给 w 添加权值,而弱化训练数据的噪声 (一般不正则化 b)
参数优化器
优化器是引导神经网络更新参数的工具
我们定义如下参数:待优化参数 w,损失函数 loss,学习率 Lr,每次迭代一个 batch,t 表示当前 batch 迭代的总次数
计算 t 时刻损失函数关于当前参数的梯度 $g_t=\nabla loss = \frac {\partial loss}{\partial(w_t)}$
计算 t 时刻一阶动量$m_t$和二阶动量$V_t$
计算 t 时刻下降梯度$\eta_t =Lr *\frac{m_t}{\sqrt V_t}$
计算 t+1 时刻下降梯度$w_{t+1} =w_t-\eta_t=w_t-Lr *\frac{m_t}{\sqrt V_t}$
一阶动量:与梯度相关的函数
二阶动量:与梯度平方相关的函数
对于不同的优化器,实质上只是定义了不同的一阶动量和二阶动量公式
SGD 优化器
SGD是最常用的随机梯度下降法,当不含动量时其定义了如下动量计算方式
$g_t$ :对应的各时刻梯度值
SGDM 优化器
在 SGD 的基础上增加一阶动量
$m_t$ : 表示各时刻梯度方向的指数滑动平均值
1 2 3 4 5 6 7 8 0 , 0 0.9 1 - beta) * grads[0 ]1 - beta) * grads[1 ]
Adagrad 优化器
其在SGD的基础上增加二阶动量
1 2 3 4 5 6 7 0 , 0 0 ])1 ])0 ] / tf.sqrt(v_w))0 ] / tf.sqrt(v_b))
RMSProp 优化器
在SGD的基础上增加二阶动量
1 2 3 4 5 6 7 8 0 , 0 0.9 1 - beta) * tf.square(grads[0 ])1 - beta) * tf.square(grads[1 ])0 ] / tf.sqrt(v_w))0 ] / tf.sqrt(v_b))
Adam 优化器
同时结合了SGDM一阶动量和RMSProp二阶动量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 0 , 0 0 , 0 0.9 , 0.999 0 , 0 0 for epoch in range (epoch): for step, (x_train, y_train) in enumerate (train_db): 1 1 - beta1) * grads[0 ]1 - beta1) * grads[1 ]1 - beta2) * tf.square(grads[0 ])1 - beta2) * tf.square(grads[1 ])1 - tf.pow (beta1, int (global_step)))1 - tf.pow (beta1, int (global_step)))1 - tf.pow (beta2, int (global_step)))1 - tf.pow (beta2, int (global_step)))
梯度下降
损失函数
特征x * w + b = y的过程被称为正向传播,而我们的目的是找到一组参数w和b,使得损失函数最小
梯度下降法 :沿损失函数梯度下降的方向,寻找损失函数的最小值,得到最优参数的方法。
学习率 (Lr):当学习率设置的过小时,收敛过程将变得分缓慢。而当学习率设置的过大时,梯度可能会在最小值附近来回震荡,甚至可能无法收敛。
梯度下降算法
$$
$$
$$
反向传播 :从S后向前,逐层求损失函数对每层神经元参数的偏导数,迭代更新所有参数
Keras 搭建神经网络
Keras是tensorflow的一个模块,用于快速搭建神经网络
1 2 3 4 5 6 7 8 9 10 11 12 13 import tensorflow as tf"激活函数" ,kernel_regularizer=正则化方式)"vaild" or "same" )
配置神经网络方法
1 2 3 4 5 6 7 8 9 10 11 12 13 model.compile (optimizer=优化器,loss=损失函数,metrics=["准确率" ])'sgd' or tf.keras.optimizers.SGD(lr=学习率,momentum=动量参数)'adagrad' or tf.keras.optimizers.Adagrad(lr=学习率)'adadelta' or tf.keras.optimizers.Adadelta(lr=学习率)'adam' or tf.keras.optimizers.Adam(lr=学习率,beta_1=0.9 ,beta_2=0.999 )'mse' or tf.keras.losses.MeanSquaredError()'sparse_categorical_crossentropy' or tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False ) 'accuracy' : y_ 与 y 都是数值,如:y_=[1 ],y=[1 ]'categorical_accuracy' : y_ 与 y 都是独热码(概率分布),如:y_=[0 ,1 ,0 ],y=[0.235 ,0.648 ,0.117 ]'sparse_categorical_accuracy' : y_是数值,y是独热码(概率分布),如:y_=[1 ],y=[0.235 ,0.648 ,0.117 ]
初学建议直接使用字符串形式的参数,对于熟悉后可以查询相关文档后使用后者,修改相关的超参数
执行训练
1 2 3 4 5 6 7 8 9 model.fit(训练集的输入特征,训练集的标签,
网络参数和结构统计
自制数据集
需要我们设计一共函数来将我们的数据集进行读入,对此我们可能需要创建对应的文件或者是对于对应的目录下的文件进行检测,对此我们需要导入 os,利用其内置库进行读写与判断,此处以读入图片进行训练为例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 import osfrom PIL import Imageimport numpy as npimport tensorflow as tfdef GenerateData (path,txt ):open (txt,'r' )for content in data:0 ] open (img_path) 'L' )) 256 1 ])print ("loading: " + img_path) return x,y_def check (x_train_savepath,y_train_savepath,x_test_savepath,y_test_savepath ):if os.path.exists(x_train_savepath) and os.path.exists(y_train_savepath) and os.path.exists(x_test_savepath) and os.path.exists(y_test_savepath):print ('-------------Load Datasets-----------------' )len (x_train_save), 28 , 28 ))len (x_test_save), 28 , 28 ))else :print ('-------------Generate Datasets-----------------' )print ('-------------Save Datasets-----------------' )len (x_train), -1 )) len (x_test), -1 ))
数据增强
数据增强可以帮助我们扩充数据集,对于图像而言就是简单的形变,可以用于应对图片拍照角度的不同而照成的一定形变
1 2 3 4 5 6 7 8 9 image_gen_train = tf.keras.preprocessing.image.ImageDataGenerator(1 -n,1 +n] )
断点续训
断点续训可以让我们训练不用每次都从头开始训练,而不用每次重头开始训练
1 2 3 4 5 6 7 8 9 True /False ,True /False )
参数提取
我们可以把参数存入文本,观察训练的参数,我们可以采用print进行输出,但是当输出信息过长时中间的部分会被省略号所替代,我们可以通过下面的函数把我们模型中可以训练的参数进行打印
1 2 3 4 5 6 7 8 9 10 11 12 13 14 print (model.trainable_variables)open ('./weights.txt' ,'w' )for v in model.trainable_variables:str (v.name)+'\n' )str (v.shape)+'\n' )str (v.numpy())+'\n' )
acc/loss 可视化
在训练过程中其实对训练集、测试集、训练集准确率、测试集准确率都有着对应的记录,我们可以将其进行提取,以可视化的方式来观察我们训练的效果
1 2 3 4 5 6 7 8 9 10
当我们拿到对应的数据后我们便可以用 matplotlib 进行绘图
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 from matplotlib import pyplot as plt 'sparse_categorical_accuracy' ] 'val_sparse_categorical_accuracy' ] 'loss' ] 'val_loss' ] 1 , 2 , 1 ) 'Training Accuracy' ) 'Validation Accuracy' )'Training and Validation Accuracy' )1 , 2 , 2 ) 'Training Loss' )'Validation Loss' )'Training and Validation Loss' )
应用
之前所用到的东西都不同于其他的程序,仅仅有了一个网络,但是要想真正运行起来需要我们编写一个应用程序,可以将我们的输入进行预测,给出一共预测的结果,在 tensorflow 中有对应的函数将我们的前向传播进行执行应用给出一个对应的预测
1 2 3 4 5 6 7 8 9 10 128 ,actvation='relu' ),10 ,activation='softmax' )
卷积神经网络
卷积就是特征提取器:卷积->批标准化->激活->池化
卷积神经网络便是借助卷积核提取特征后送入全连接网络
卷积计算过程
卷积计算那是一种有效提取图像特征的方法
一般会用一个正方形的卷积核,按指定步长,在输入特征图上滑动,遍历输入特征图中的每个像素点。每一个步长,卷积核会与输入特征图出现重合区域,重合区域对应元素相乘、求和再加上偏置项得到输出特征的一个像素点
输入特征图的深度(channel数),决定了当前层卷积核的深度;当前层卷积核的个数,决定了当前层输出特征图的深度。
对应元素相乘之后求和再加上对应的偏置项 b
感受野(Receptive Field)
卷积神经网络各输出特征图中的每个像素点,在原始输入图片上映射区域的大小。
全零填充(Padding)
卷积计算保持输入特征图的尺寸不变可以使用全零填充
卷积核计算
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 tf.keras.layers.Conv2D("same" or "valid" "relu" or "sigmoid" or "softmax" or "tanh" 6 ,5 ,padding='valid' ,activation='sigmoid' ),2 ,2 ),6 ,(5 ,5 ),padding='valid' ,activation='sigmoid' ),2 ,(2 ,2 )),6 , kernel_size=(5 ,5 ),padding='valid' ,activation='sigmoid' ),2 ,2 ),strides=2 ),10 ,activation='softmax' )
批标准化(BN)
标准化:使数据符合 0 均值, 1 为标准差的分布
批标准化:对一小批数据(batch)进行标准化处理,常用在卷积和激活之间
卷积 -> 批标准化 -> 激活
1 2 3 4 5 6 7 8 9 tf.keras.layers.BatchNormalizaton()6 ,kernel_size=(5 ,5 ),padding='same' ),'relu' ), 2 ,2 ),strides=2 ,padding='same' ), 0.2 )
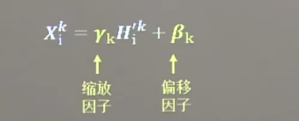
批标准化操作会让每个像素点进行减均值除以标准差的自更新计算,在经过标准化操作后将其重新拉回到 0 均值,数据更集中于激活函数的线性区域,提升了激活函数对输入数据的区分力
但是简单的数据标准化使特征数据完全满足了正态分布,集中在激活函数中间的线性区域,使激活函数失去了非线性特性,因此BN操作中为每个卷积核引入了两个可训练参数用于控制缩放和偏移
在反向传播中使其一起被优化,进而优化数据的分布
池化
池化操作用于减少卷积神经网络中特征数据量,最大值池化可提取图片纹理,均值池化可保留背景特征。
最大池化:将池化核中的最大值进行保留
1 2 3 4 5 tf.keras.layers.MaxPool2D("same" or "valid"
均值池化:将池化核中的数据的平均值进行替代
1 2 3 4 5 tf.keras.layers.AveragePooling2D("same" or "valid"
舍弃
在神经网络训练时,将将隐藏层的一部分神经元按照一定概率从神经网络中暂时舍弃。神经网络使用时,被舍弃的神经元恢复链接。
1 tf.keras.layers.Dropout(舍弃的概率)
循环神经网络
使用循环神经网络实现连续数据的预测,即借助循环核提取时间特征后送入全链接网络
循环核
参数时间共享,循环层提取时间信息
循环计算层
循环计算层向输出方向生长
1 2 3 4 5 6 tf.keras.layers.SimpleRNN(记忆体个数,activation='激活函数' ,return_sequences=是否每个时刻输出ht到下一层) 3 ,return_sequences=True )
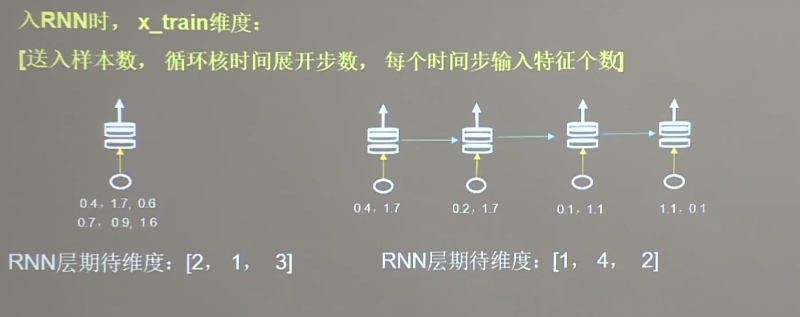
入RNN时,x_train维度:[送入样本数,循环核时间展开步数,每个时间步输入特征个数]
Embedding 单词编码
独热码:数据量大过于稀疏,映射之间是独立的,没有表现出关联性
Embedding:是一种单词编码方法,用低维向量实现了编码,这种编码通过神经网络训练优化,能表达出单词间的相关性。
1 tf.keras.layers.Embedding(词汇表大小,编码维度)
编码维度就是用几个数字表达一个单词
对1-100进行编码,[4]编码为[0.25,0.1,0.11]
例:tf.keras.layers.Embedding(100,3)
入Embedding时, x_train维度:[送入样本数,循环核时间展开步数]
LSTM 长短记忆网络
$W_i$、$b_i$、$W_f$、$b_f$、$W_o$、$b_o$均为待训练参数,再Sigmoid函数的作用下归一化
门限取值范围为(0,1)
1 2 3 tf.keras.layers.LSTM(记忆体个数,return_sequences=是否返回输出)
GRU 网络
GRU使记忆体 ht 融合了长期记忆和短期记忆
1 2 3 tf.keras.layers.GRU(记忆体个数,return_sequences=是否返回输出)